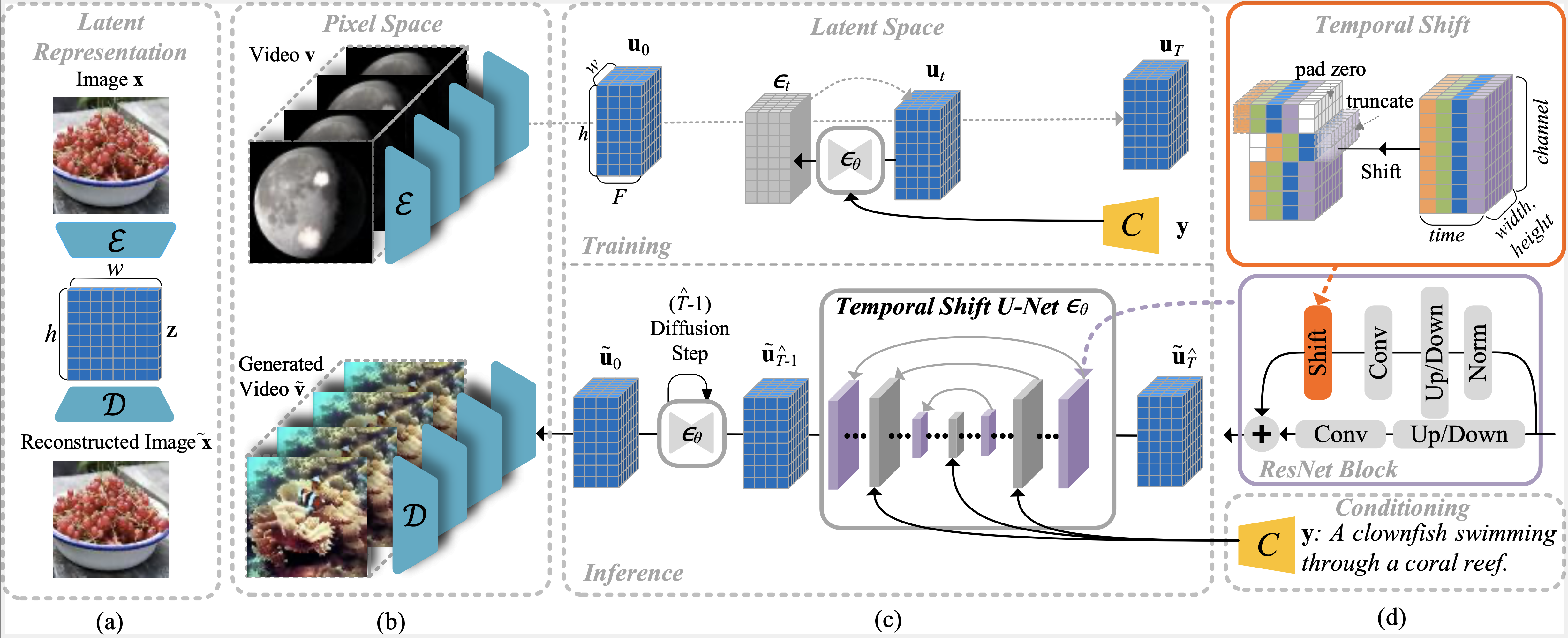
An illustration of our framework. From left to right: (a) An autoencoder is trained
on images to learn latent representation. (b) The pretrained autoencoder is adapted
to encode and decode video frames independently. (c) During training, a temporal
shift U-Net $\epsilon_\theta$ learns to denoise latent video representation at a uniformly
sampled diffusion step $t\in [1,T]$. During inference, the U-Net gradually denoises from a
normal distribution from step $\widehat{T}-1$ to $0$ where $\widehat{T}$ is the number of
resampled diffusion steps in inference. (d) The U-Net $\epsilon_\theta$ is composed
of two key building blocks: the $2$D ResNet blocks with convolutional layers, highlighted in
violet, and the transformer blocks with spatial
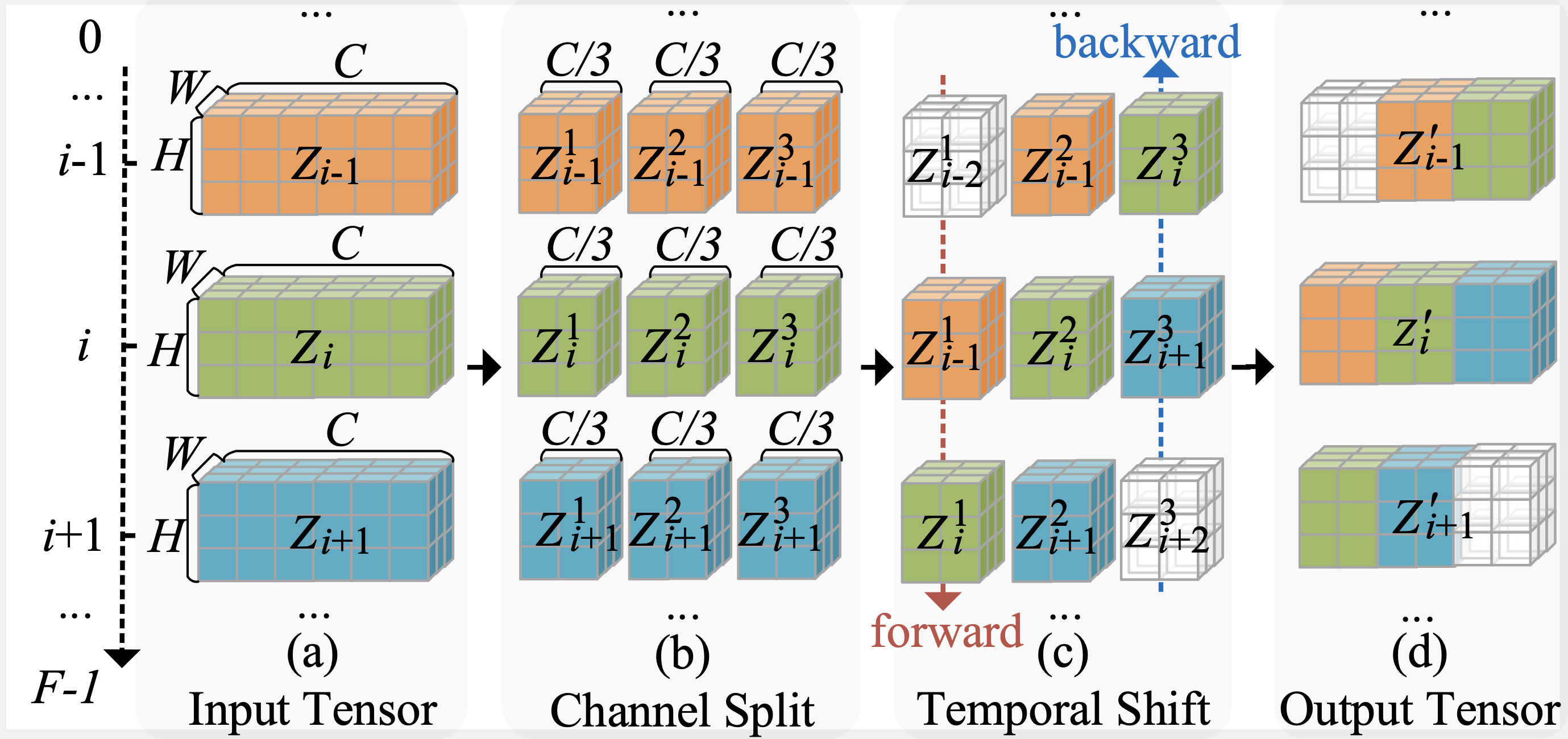
attention layers, colored in gray. The temporal
shift module, highlighted in red, shifts the feature
maps along the temporal dimension. It is inserted into the residual branch of each $2$D
ResNet block. The text condition is applied to the transformer blocks via cross-attention.
The channel dimension $c$ in the latent space representation of $\mathbf{z}$ and
$\mathbf{u}$ are omitted for clarity.